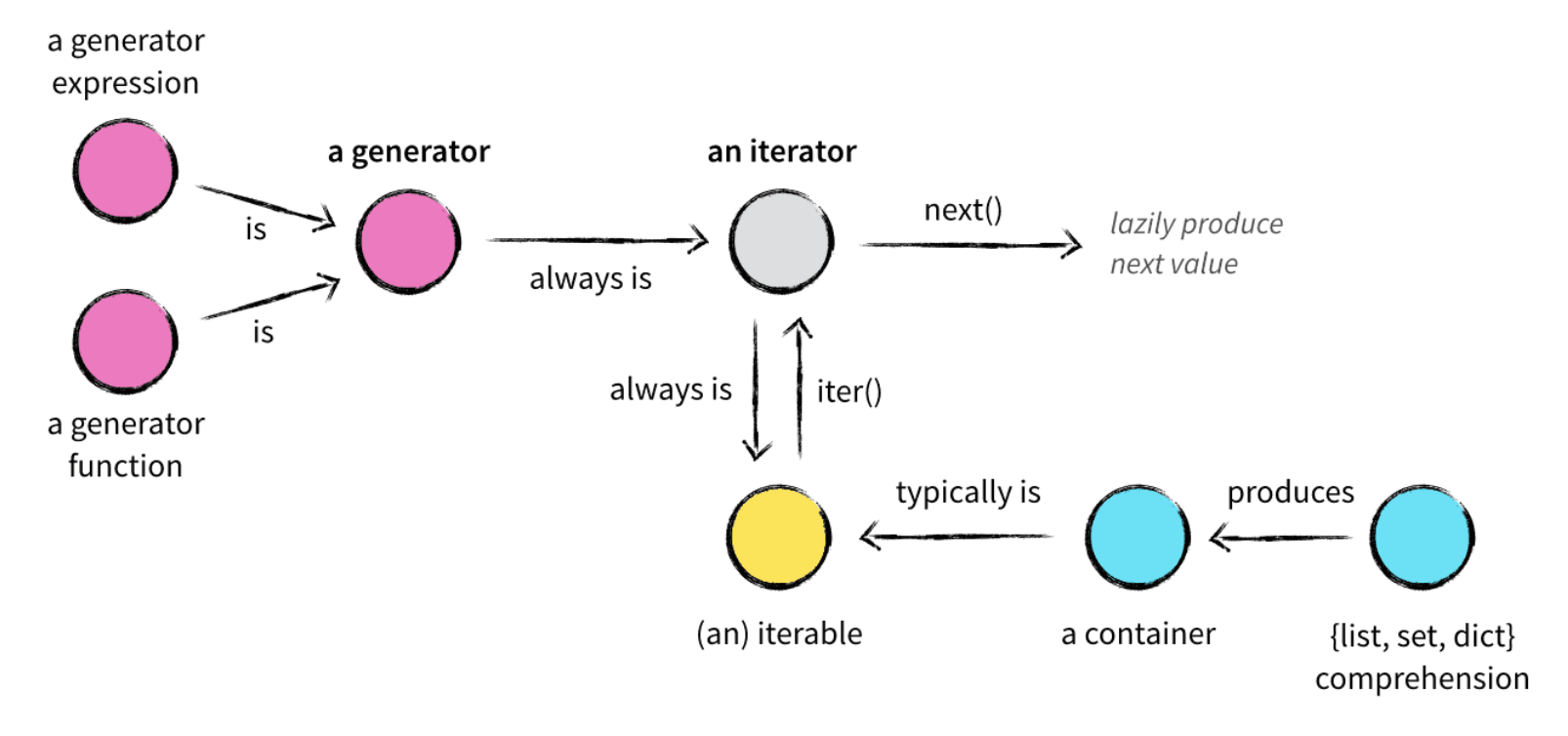
可迭代对象
概念
内部实现了__iter__()方法
验证方法
- 使用dir()方法查看数据类型中的方法是否包含
__iter__()
作用
- 可迭代对象执行
__iter__()方法后会生成一个迭代器对象
标识
- 拥有
__iter__()方法的对象
示例
1 | s = 'abc' # 可迭代对象 |
迭代器
概念
迭代器是一个有状态的对象,它能在调用next()方法的时候返回容器中的下一个值,任何实现了__iter__()和__next__()方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有下一个值则抛出StopIteration异常。
迭代器 vs 可迭代对象区别
迭代器拥有
__length_hint__: 获取迭代器中元素的长度迭代器拥有
__setstate__: 根据索引值指定从哪里开始迭代迭代器拥有
__next__: 获取迭代器对象的下一个值
标识
- 拥有
__iter__()和__next__()方法的对象
示例
1 | s = 'abc' |
生成器(本质是迭代器)
概念
生成器是一种特殊的迭代器,它用于创建迭代器的简单而强大的工具。 它们的写法类似标准的函数,但当它们要返回数据时会使用yield语句。 每次对生成器调用next()时,它会从上次离开位置恢复执行(它会记住上次执行语句时的所有数据值)。
特点
- 惰性运算,开发者自定义
- 本质是迭代器
应用
生成器函数
一个包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。生成器函数进阶:
send()- send和next的作用相同
- 第一次不能用send
- 函数中的最后一个yield不能接受新的值
生成器表达式
类似于列表推导,但是生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表。
示例
- 简单应用
1 | import time |
- 避免一次性读取数据到内存中导致内存溢出
1 | import time |
- yield from
1 | def gen1(): |
- 生成器函数进阶:
send()
1 | # 计算移动平均值的例子 |
- 预激生成器的装饰器
1 | # 预激生成器的装饰器——在装饰器中首先调用了__next__方法,方便用户直接进行调用 |
- 推导式汇总
1 |
|
关系图